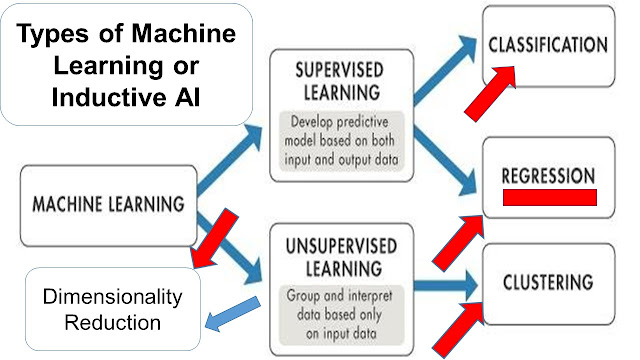
Comparação entre R e SAS no Brasil - IA Generativa
Comparação entre R e SAS no Brasil - IA Generativa Prompt: Comparação entre R e SAS no Brasil IA Gemini Data: 26/3/2025 Comparação entre SAS e R no Brasil A utilização de SAS e R no Brasil reflete uma tendência global, mas com nuances específicas do mercado brasileiro. Ambas as ferramentas são amplamente utilizadas para análise de dados, mas possuem características e aplicações distintas. SAS Histórico e Mercado : SAS tem uma longa tradição no mercado brasileiro, especialmente em setores como bancos, finanças e saúde. Sua reputação de confiabilidade e suporte técnico robusto o torna uma escolha frequente para empresas que lidam com dados críticos e precisam de soluções estáveis e auditáveis. Vantagens: Confiabilidade e estabilidade. Suporte técnico especializado. Documentação abrangente. Adequado para grandes volumes de dados e aplicações empresariais. Desvantagens: Custo elevado de licenciamento. Menor flexibilidade e capacidade de personalização em comparação com R. Curva ...